Basics Filtering
Filtering vertex and edge routes
Vertex and edge routes can be filtered based on properties value(s).
# Find vertices whose 'name' property has value 'Bob'
graph.v(name: 'Bob')
# Find edges whose 'foo' property has value 'bar'
graph.e(foo: 'bar')
# Find vertices whose 'name' property is either 'Alice' or Bob'
graph.v(name: Set['Alice', 'Bob'])
# Find vertices whose 'name' property is either 'Alice' or Bob', and 'age' is 30
graph.v(name: Set['Alice', 'Bob'], age: 30)
Edge routes can also be filtered by edge label.
# Find edges whose label is 'related_to'
graph.e(:related_to)
# Filter by label and property
g.e(:flies_to, airline: 'Delta')
Combining basic filtering methods, allow us to define meaningful traversals.
For example, we can define the following routes in a social network graph.
# Find followers of users that Bob follows
graph.v(type: 'user', name: 'Bob').out_e(:follows).in_v(type: 'user').in_e(:follows).out_v(type: 'user')
filter
Consider the following filter
g.v(gender: 'female', age: 30)
If we want to apply the filter to an arbitrary collection of vertices (instead of all vertices in the graph), we can use the filter method.
def thirty_years_old_females(people)
people.filter(gender: 'female', age: 30)
end
The filter method works just as you'd expect:
filter(foo: 'a') - Include items whose foo property is a.filter(foo: 'a', bar: 'b') - Include items whose foo property is a and bar property is b.filter(foo: Set['a', 'b']) - Include items whose foo property is either a or b.filter(foo: Set['a', 'b'], bar: 'c') - Include items whose foo property is either a or b, and bar property is c.
where
With where you can produce more sophisticated conditions against an individual element. The where method uses JRuby's own parser for fast and
robust parsing, but reinterprets the expressions in the where clause to build graph traversals instead of Ruby code. The where method only uses a
subset of Ruby's syntax features, and any unsupported expression will raise an exception. No code may be executed through where statements, and they
also can not be used to modify data (unlike SQL or Cypher).
Usage:
where("age = 27")where("age = :age", age: 27) always use this with user input to avoid injection attacks.
Despite being save from arbitrary code execution or direct modification, a malicious user could still theoretically inject a where statement to
bypass your security. For instance: where("user_id == '#{ user_id }'") could be given the input ' or user_name == 'admin which would produce the
statement where("user_id == '' or user_name == 'admin'"). Using where("user_id == :id", id: user_id) eliminates that risk.
The following pieces of Ruby syntax are valid in a where clause:
< > <= >= == != # comparisons
= # used as a comparison where syntactically allowed
and or not && || ! # boolean logic
+ - * / % # simple mathematical expressions
( ) # expression grouping
:symbol # symbols are replaced by user values
123 123.45 # numeric constants
"abc" 'abc' # string constants
true false nil [] {} # boolean, nil, array, or hash constants
filter with a block of code
So far, we have seen two types of filtering:
- Using
filter - Fast, but limited. The filtering condition is limited to exact property matches, logical-AND and logical-OR.
- Using
where - Not as fast (but still fast), but more expressive.
The where statement is fairly expressive, but it is still somewhat limited. To get full expressiveness, you can filter items using a block of Ruby code. This is the most powerful, but also the most expensive (in terms of performance), way of filtering.
Usage:
filter { |element| } same as selectselect { |element| } keep elements when the block result is truthy.reject { |element| } eliminate elements when the block result is truthy.
Example:
graph.v.filter { |v| v[:name] == v[:name].reverse } # find palindromic names.
Filtering with a block of code is noticeably slower than the previous two methods, because it has to go through Pacer's element wrapping process. Unlike the other two methods, which are executed in pure Java.
filtering large collections could be several times slower. For smaller collections the impact is
negligible, however.
Filtering based on a collection of items
only and except
If you have a collection of elements or a route to some elements that you want to include or exclude from a traversal, you can do that with these
methods.
Usage:
r.only(collection_or_route)r.except(collection_or_route)
Note: If you pass a route to these methods, it will be evaluated immediately into a Set of elements.
is and is_not
These methods are similar to only and except. The difference is that they filter based on a single elements, instead of a collection.
Usage:
is(element)is_not(element)
as together with is or is_not
Consider the following traversal, defined in a hypothetical social network application.
# Return other users who commented on any of the given user's post
def commenters(user)
user.out_e(:posted).in_v
.out_e(:comment).in_v
.in_e(:posted).out_v
.is_not(user)
end
The traversal above works as follows:
- Get the
user's posts.
- Then comments to these posts.
- Then users who posted these comments.
- And exclude
user from the result.
The traversal above works well when user is a single vertex, but what if we want it to be more flexible, and allow user to be a route?
At first glance, it seems like a trivial change - Instead of is_not, which excludes a single element, use except, which does the same for a collection/route.
def commenters(users)
users.out_e(:posted).in_v
.out_e(:comment).in_v
.in_e(:posted).out_v
.except(users)
end
There is a subtle performance issue with the code above - The users route is being evaluated twice:
- When Pacer builds the route, in
except(users).
- When Pacer evaluates.
When we say "evaluate a route", we mean "stream the elements out of the
underlying graph database and into your application.
Depending on the underlying database, this can be a costly operation.
We can avoid this inefficiency using the as method.
The as method allows you to name an intermediate route, and refer to it later with is or is_not:
def commenters(users)
users.as(:posters)
.out_e(:posted).in_v
.out_e(:comment).in_v
.in_e(:posted).out_v
.is_not(:posters)
end
The most intuitive way to reason about this code is by thinking of
a route as a pipeline.
- During the build stage, Pacer names an intermediate point in the pipeline as
:posters.
- During the evaluation phase, graph elements flow through the pipeline.
- The last step in the pipeline,
is_not(:posters), checks if the an element
passed through the :posters part of the pipeline.
If it did, the element is excluded from the result.
Usage:
as(:a_name), traverse, then is(:a_name)as(:a_name), traverse, then is_not(:a_name)
Note: We can call as on a single item, as well as a route.
In both cases, when we refer to the named item/route, we use is/is_not (instead of only/except).
In the example above, users can be either a single element or a route.
random
random filters out items randomly. It is useful for random sampling, as well as generating random walks through the graph.
The random method takes a single numeric argument.
The argument is the probability of an item being emitted (i.e. not filtered).
# Each item will be included in the result with probability 0.2
g.v.random(0.2)
# If the argument is greater than 1, the probability is its reciprocal.
# For example, included each item with probability of 1/4 = 0.25
g.v.random(4)
# The following examples are fairly useless:
g.v.random(1) # Include all items
g.v.random(0) # Exclude all items
# If the argument is negative, it is treated as 0 (and all items are excluded from the result).
Note: If our collection is large, we can expect random(0.2) to emit 20% of the items in the collection (aka Law of large numbers ).
most_frequent
Return the items that occurs most frequently in a route.
Usage
most_frequent, return a most frequent item.most_frequent(num), return the num most frequent item.
That is, most_frequent(0) returns the most frequent item, most_frequent(1) the second most frequent, most_frequent(2) the third and so on.most_frequent(a..b), return (a route containing) items a to b (inclusive) in the most-frequent list.
For example, most_frequent(1..2) will return (a route containing) the second and third most frequent items.most_frequent(num, truthy_value), same as most_frequent(num), but also includes the count (not just the item).most_frequent(range, truthy_value), same as most_frequent(range), but also includes a count of each item.
Example
def recommend_books(user)
# Recommend book that are liked by my friends.
user.out_e(:friend).in_v.out_e(:likes_book).in_v.most_frequent(5)
end
lookahead
The lookahead filter is extremely useful - It allows us to filter items based on a walk through the graph.
For example, in a social network, we may want a filter that gets a collection of users (i.e. vertices), and emits only those users that are followed by more than 1000 people.
The following diagram explains how a lookahead filters each incoming item:
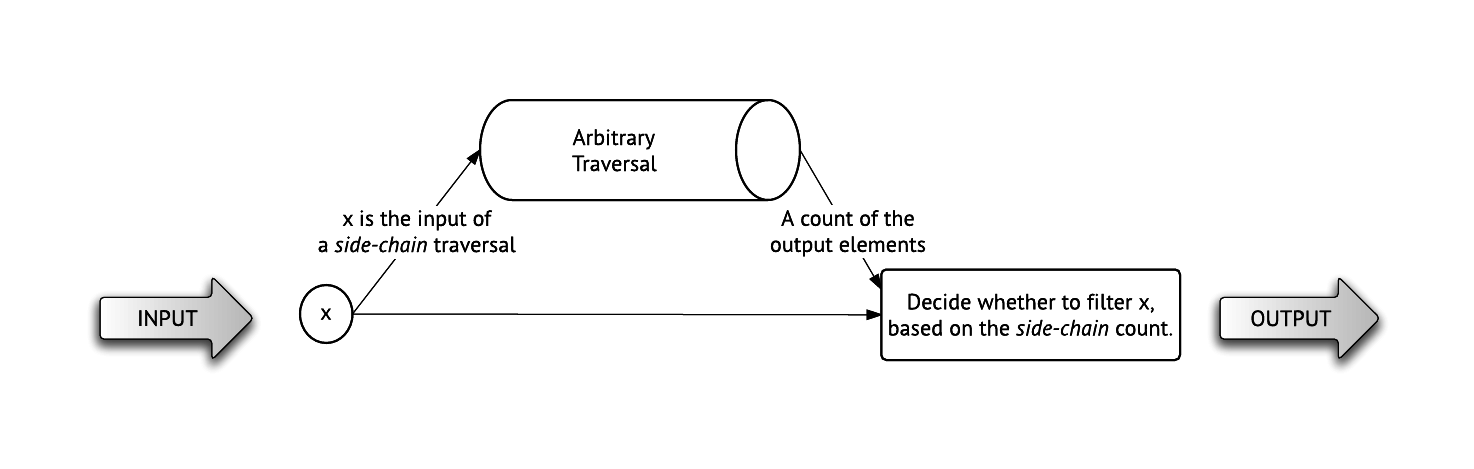
In code, lookaheads can be used as follows:
lookahead(min: 2, max: 5) {|v| v.out_e} - Keeps vertices that have between 2 to 5 outgoing edges.lookahead(min: 10) {|v| v.out_e} - Keeps vertices with at least 10 outgoing edges.lookahead(max: 10) {|v| v.out_e} - Keeps vertices with at most 10 outgoing edges.lookahead {|v| v.out_e} - Keeps vertices with at least 1 outgoing edge (equivalent to lookahead(min: 1).
Notice that the side-chain traversal (i.e. the block of code) can as complex as you need it to be. Here are a few examples:
# Get all flights that land in Toronto
r = g.e(:flies_to).lookahead {|flight| flight.in_v(city: 'Toronto')}
# Or the airlines that operate such flights
g.e(:flies_to).lookahead {|flight| flight.in_v(city: 'Toronto')} [:airline].uniq
# Get popular users in a social network
g.v(type: user).lookahead(min: 1000) {|u| u.in_e(:follows)}
A note on efficiency
Lookaheads are efficient, they do as much work as needed, but no more than that. That is, the side-chain traversals of lookahead(min:10) will stop as soon as 10 items are found. Similarly, the side-chain traversal of lookahead(max: 3) will stop as soon as it finds 4 items.
neg_lookahead
The neg_lookahead filter (negative lookahead) excludes items whose side-chain traversal contains at least one item. Negative lookaheads work just like regular lookaheads (i.e. they accept a min and max argument), but, in terms of coding style, we recommend to only use them when you need to "reverse" a filter.
For example, we can define a 'not_popular' filter, based on a popular filter:
def popular(users)
users.lookahead(min: 1000) {|u| u.in_e(:follows)}
end
def not_popular(users)
# Each user that is included in the popular results, will be excluded by neg_lookahead
users.neg_lookahead {|u| u.popular}
end