In addition to the basic traversal methods (following edges and/or vertices),
Pacer routes have a few convenient methods that allow you to easily build more complex traversals.
branch
Let's continue with our simple graph, containing airports and flights.
Now, suppose we want to find all cities we can reach by taking at most two flights from La Guardia Airport.
Essentially, what we want to do is:
# Find the vertex that corresponds to La Guardia airport
v = g.v(airport: 'LGA')
one_flight = v.out_e.in_v[:city]
two_flights = v.out_e.in_v.out_e.in_v[:city]
# Take the union of the two routes, one_flight and two_flights, somehow ...
When we want to take the union of two (or more) routes, we use branch.
The diagram below describes how a branch route works.
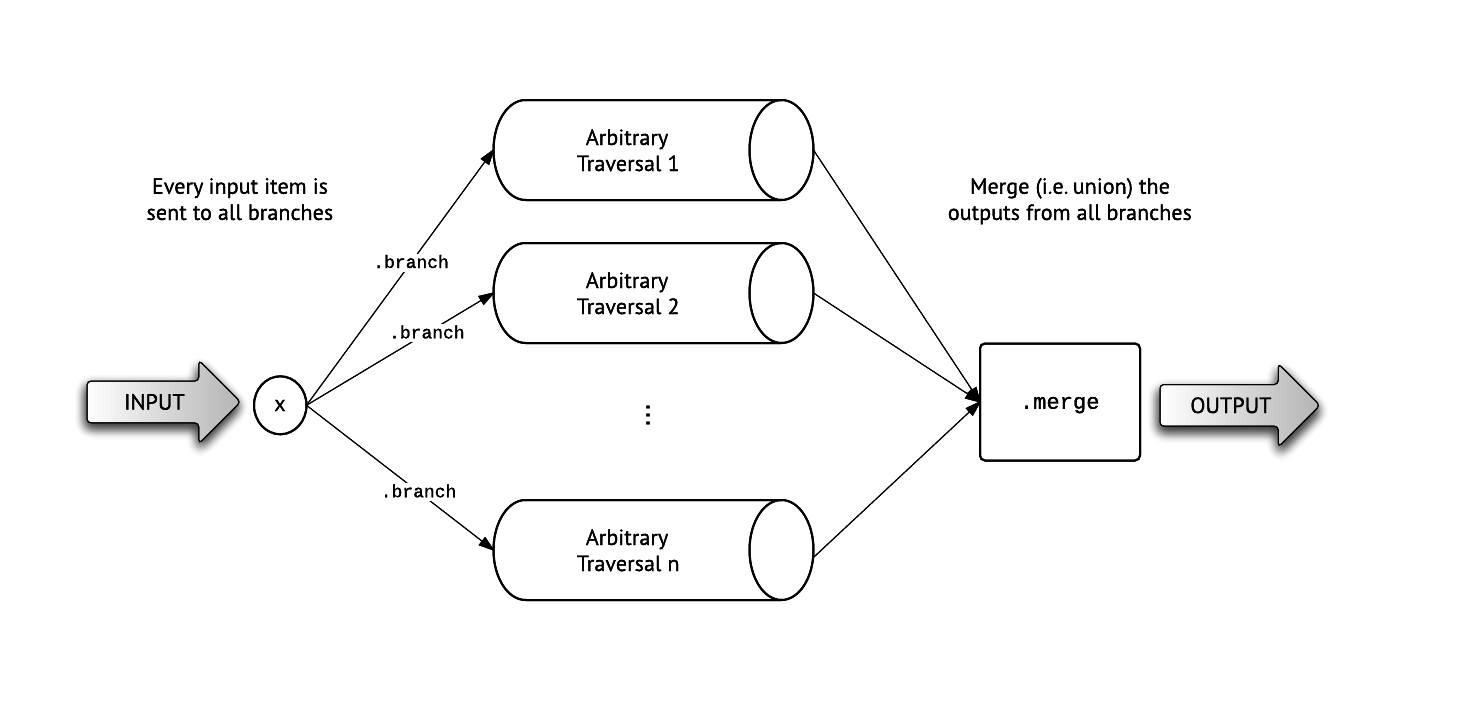
Usage:
branch { |route| }.branch { |route| }.merge
Example:
def at_most_two_flights_away(v)
v.out_e.in_v.branch do |airports|
airports[:city]
end.branch do |airports|
airports.out_e.in_v[:city]
end.merge
end
Let's look at this traversal more closely:
* v.out_e.in_v is a route of vertices - All airports that are one flight away from La Guardia.
* Our first branch, returns (a route containing) the city of each airport.
* Out second branch, traverses to airports that are an additional flight away, using airports.out_e.in_v, and gets the city property.
* We finish by merging the two traversals.
Note: Calling merge is not strictly necessary, but is a good idea.
For example, if you try to do two 2-way branches in a row, without a merge statement between them, you will accidentally produce one 4-way branch. This is an easy mistake to make if you build the branches with helper methods.
merge vs. merge_exhaustive
Pacer provides two different ways to merge the items from branches. The difference between the two methods is the order of the output items.
merge (default) uses a round-robin strategy.merge_exhaustive completely exhaust each branch in order, before starting on the next one.
identity
Let's take another look at the following code example:
def at_most_two_flights_away(v)
v.out_e.in_v.branch do |airports|
airports[:city]
end.branch do |airports|
airports.out_e.in_v[:city]
end.merge
end
If you hate repeated code as much as I do, you may want to get rid of the repeated [:city], and write the code as:
def at_most_two_flights_away(v)
v.out_e.in_v.branch do |airports|
airports
end.branch do |airports|
airports.out_e.in_v
end.merge[:city]
end
If you try running the code above, you will get an error.
This is because each branch block is required to build a route (or, if you look at the diagram above, "all of the pipes must exist").
The identity route is useful for situations like this. We can fix the above code as follows:
def at_most_two_flights_away(v)
v.out_e.in_v.branch do |airports|
airports.identity
end.branch do |airports|
airports.out_e.in_v
end.merge[:city]
end
loop
Looping is a fairly basic concept in programming. In Pacer, and the world of graph databases in general,
looping means "repeating traversal patterns". For example:
- Starting from an airport, look for a departing flight, get its destination airports, and repeat.
- In an ancestry tree, go two levels up (to your grandparents), then two levels down (to all of their grandchildren), repeat this process.
The diagram below describes how a loop/while route works:
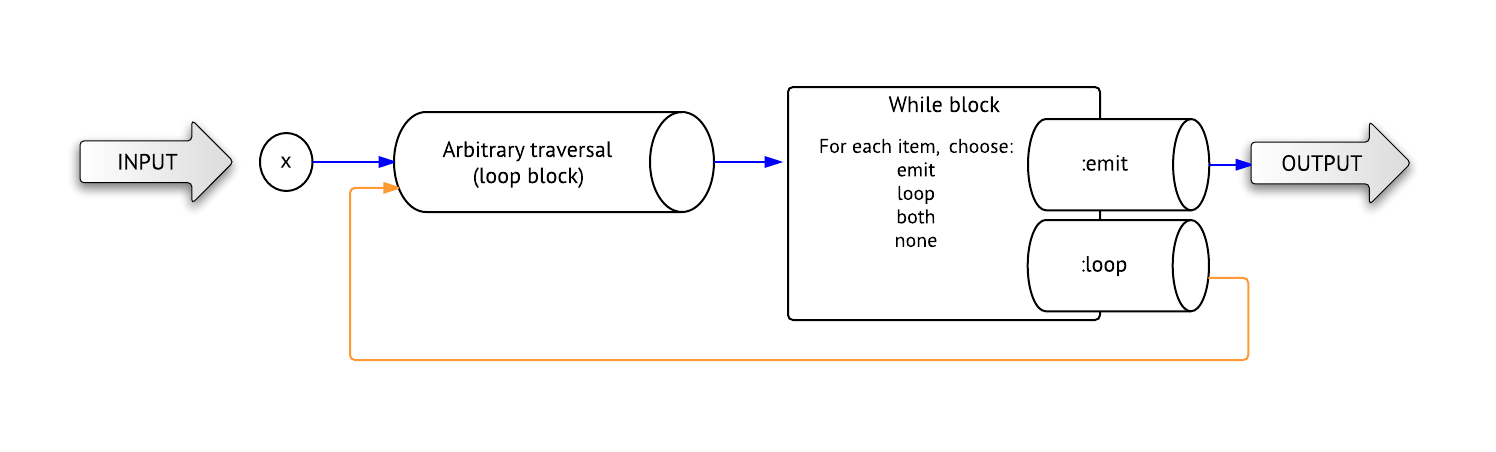
Unlike most routes, loop requires 2 blocks:
loop block, containing some arbitrary traversal that will be repeated. while block that determines whether to feed an item back to the loop block, as well as whether to emit the item (i.e. include the item in the output).
Usage:
loop { |route| arbitrary_steps(route) }.while { |element, depth| }loop { |route| arbitrary_steps(route) }.while { |element, depth, path| }
Important: Keeping track of paths requires more memory. If you do not use path in the while-block, you should follow the first usage pattern.
route and arbitrary_steps(route) must be routes of the same type.
E.g. If route is a vertex-route, but arbitrary_steps(route) results in an edge-route, Pacer will raise an error.
The while block arguments are:
element - An element going into the while-block.depth - The number of times Pacer applied the loop block, in order to get to this element.
Source elements have a depth of 0path - An array of vertices and edges, the full path to this element.
The while block controls the loop by returning one of these values:
:loop = do not emit the element into the results of this traversal, but feed it back through the loop.:emit = emit the element into the results of this traversal, but do not feed it back through the loop.:loop_and_emit = emit the element and feed it back through the loop.:emit_and_loop = same as :loop_and_emit (because we can never remember which one to use).nil or false = don't emit this element and don't feed it back through the loop.
Example:
def reachable_via_at_most_n_flights(airport, n)
airport.loop do |r|
r.out_e.in_v
end.while do |airport, depth|
if depth == 0
:loop
elsif depth <= n
:loop_and_emit
else
false
end
end
Pacer has a few convenience methods that wrap around its loop traversal.
all
Repeat a certain traversal pattern, and return all elements you encounter.
This method is equivalent to calling loop, with the while block { :emit_and_loop }.
Usage:
all { |route| arbitrary_steps(route) }
deepest
Repeat a certain traversal pattern, but return only the deepest elements in the full traversal.
Usage:
deepest { |route| arbitrary_steps(route) }
breadth_first
Traversals typically work through the graph in depth-first order. Pacer implements simple hack to allow efficient breadth-first searches with repeating traversals.
This resulting route will have the same items as all, but the order will be different.
Usage:
breadth_first { |route| arbitrary_steps(route) }
section
Consider the following traversal, in a hypothetical social network application:
def suggest_bands(user_vertex)
# Recommend all the bands that your friends like
user_vertex.out_e(:friend).in_v.out_e(:likes_band).in_v
end
Now, let's make things interesting, and try to get at most two bands from each friend.
limit_section
First of all, let's see the solution:
user_vertex.out_e(:friend).in_v.section(:foo)
.out_e(:likes_band).in_v
.limit_section(:foo, 2)
What happened here?
- The call to
section(:foo) marks the route user_vertex.out_e(:friend).in_v as a section called foo.
- Later in the traversal, we can use the name
foo to group items.
- The items we traverse from each vertex in
user_vertex.out_e(:friend).in_v are groups together.
- The call to
.limit_section(:foo, 2) means two things:
- For each friend (in the
foo section), treat the bands that they like as one group.
- Limit the size of each group to 2 bands.
Usage:
limit_section(:section_name, the_limit)
sort_section
Similarly to limit_section, we can sort the items in a section. This can be extremely useful when traversing very large data set.
Usage:
sort_section(:section_name)sort_section(:section_name) { |element| value_to_sort_by(element) }
Example:
level2 = level1.section(:level1).out.out.sort_section(:level1) { |v| v[:key] }
result = level2.section(:level2).out.out.sort_section(:level2) { |v| v[:key] }
count_section
Count the number of items in each section.
Usage:
count_section(:section_name)
Example:
# How many bands does each of your friends like?
user_vertex.out_e(:friend).in_v.section(:foo)
.out_e(:likes_band).count_section(:foo)
uniq_in_section
The same way we can sort or limit the items in each section, we can also ask to remove duplicate items.
Usage:
uniq_in_section(:section_name)